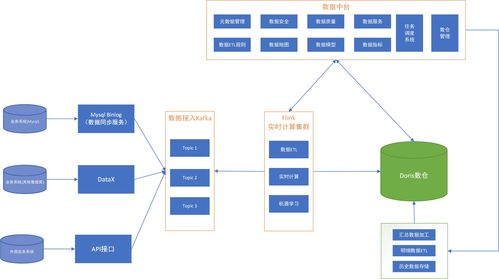
随着数据驱动决策在企业和科研领域的普及,Python3 凭借简洁的语法和强大的库生态成为数据处理的首选语言。其中,面向对象编程(OOP)不仅提升了代码的可维护性,还为构建高效的数据处理服务提供了坚实基础。本文将结合实例探讨如何利用 Python3 的 OOP 特性设计数据处理服务。
一、面向对象编程核心概念在数据处理中的体现
面向对象编程基于类、对象、封装、继承和多态等概念,这些在数据处理服务中具有实际应用价值:
- 类与对象:可定义一个
DataProcessor类,将数据加载、清洗、转换等操作封装为方法,每个数据处理任务实例化为对象,如sales_processor = DataProcessor('sales.csv')。 - 封装:通过私有属性和方法隐藏数据处理的内部逻辑,例如在类中设置
<em>clean</em>data()方法,外部仅通过公共接口调用,避免数据被意外修改。 - 继承:可创建基础类如
BaseDataService,定义通用方法(如数据验证),再派生出特定子类如TimeSeriesProcessor来处理时间序列数据,减少代码冗余。 - 多态:允许不同子类实现相同接口,例如
export_data()方法在CSVExporter和JSONExporter子类中有不同实现,提升服务的灵活性。
二、构建数据处理服务的实践步骤
以构建一个简单的数据清洗服务为例,我们可以按以下步骤实现:
- 定义类结构:创建一个
DataCleaningService类,初始化时接收数据源路径。 - 封装方法:在类中添加方法如
load<em>data()(使用 pandas 库读取数据)、remove</em>duplicates()(去除重复项)、fill<em>missing</em>values()(填充缺失值)等,每个方法处理特定任务。 - 错误处理:通过 try-except 块封装数据处理逻辑,例如在
load_data()中捕获文件未找到异常,确保服务健壮性。 - 扩展性设计:利用继承创建自定义处理器,例如从
DataCleaningService派生TextDataCleaner子类,重写清洗方法以处理文本数据。
三、实例代码:简单数据处理服务
以下是一个 Python3 代码示例,展示如何使用 OOP 构建数据处理服务:`python
import pandas as pd
class DataProcessor:
def init(self, filepath):
self.filepath = filepath
self.data = None
def loaddata(self):
"""加载数据"""
try:
self.data = pd.readcsv(self.filepath)
print("数据加载成功")
except FileNotFoundError:
print("文件不存在,请检查路径")
def cleandata(self):
"""基础清洗:去重和填充缺失值"""
if self.data is not None:
self.data.dropduplicates(inplace=True)
self.data.fillna(method='ffill', inplace=True)
print("数据清洗完成")
def get_summary(self):
"""返回数据摘要"""
return self.data.describe() if self.data is not None else None
使用示例
processor = DataProcessor('example.csv')
processor.loaddata()
processor.cleandata()
print(processor.get_summary())`
在这个例子中,我们封装了数据加载和清洗流程,通过对象方法调用来执行任务。
四、优势与最佳实践
采用 OOP 构建数据处理服务的主要优势包括:
- 模块化:将功能分解为独立类和方法,便于测试和调试。
- 可重用性:通过继承和多态,服务可快速适配新数据类型。
- 维护性:封装细节后,代码更易于理解和扩展。
最佳实践建议:
- 使用类型提示(如
from typing import List)提高代码可读性。 - 结合 Python 库如 pandas 和 NumPy 优化性能。
- 编写单元测试验证每个类的方法,确保数据处理准确性。
总结,Python3 的面向对象编程为数据处理服务提供了结构化和高效的开发范式。通过合理应用 OOP 原则,开发者可以构建出可扩展、易维护的数据处理系统,满足从简单清洗到复杂分析的各种需求。随着项目规模扩大,这种设计将显著提升团队协作效率和代码质量。